B2B Data
18 min read
What Is B2B Data Validation? The Complete 2026 Guide to Cleaner Data & Higher ROI

Arezoo Moghaddam

Most B2B companies believe they’re actually validating their data by checking the format of their emails, eliminating a few obvious duplicates. That’s it, and then they call it a day. This is not validation; this is guessing at best.
B2B data validation is the practice of ensuring that your business contact and company information is accurate, complete, formatted correctly, and actually usable before it enters a sales cycle, marketing campaign, or analytics platform. Without data validation, every business decision your revenue team makes is based on data you can’t trust.
And the price of that misplaced trust adds up quickly. Bad data doesn’t just lie there in your CRM; it multiplies. Each bounced email erodes your sender reputation. Each call to an unconnected number erodes your SDR’s time. Each campaign sent to the wrong job title erodes the budget that could have closed a sale.
This guide will walk you through what B2B data validation actually entails, debunk five myths that are quietly killing your pipeline, provide a prioritization framework that most teams have never considered, and provide a step-by-step playbook on how to do it right.
What B2B Data Validation Really Means (And What It Doesn't)
Data validation is a fancy term, but essentially it all boils down to this: can you actually use this record?
It means that you're verifying not only that the email address looks good, but that it actually exists, is in use, and can actually receive mail. It means that you're verifying that the person in your CRM still has the same job title that you're trying to market to them for. It means that you're verifying that the company's revenue, employee count, and industry classification are actually accurate, and not what they were eighteen months ago when someone brought in a list.
Validation checks every field against a set of rules and trusted external sources. When a record passes, your team can take action on it with confidence. If not, you've prevented a problem from costing you money before it even happens.
This is what makes validation better than hope.
Validation vs. Cleansing vs. Enrichment: The Distinction That Matters
These three words are thrown around as if they’re interchangeable, and this causes problems. A team is running a cleansing project and thinks its data is validated. Or they’re spending money on enrichment without understanding that the underlying records they’re enriching have never been validated to begin with.
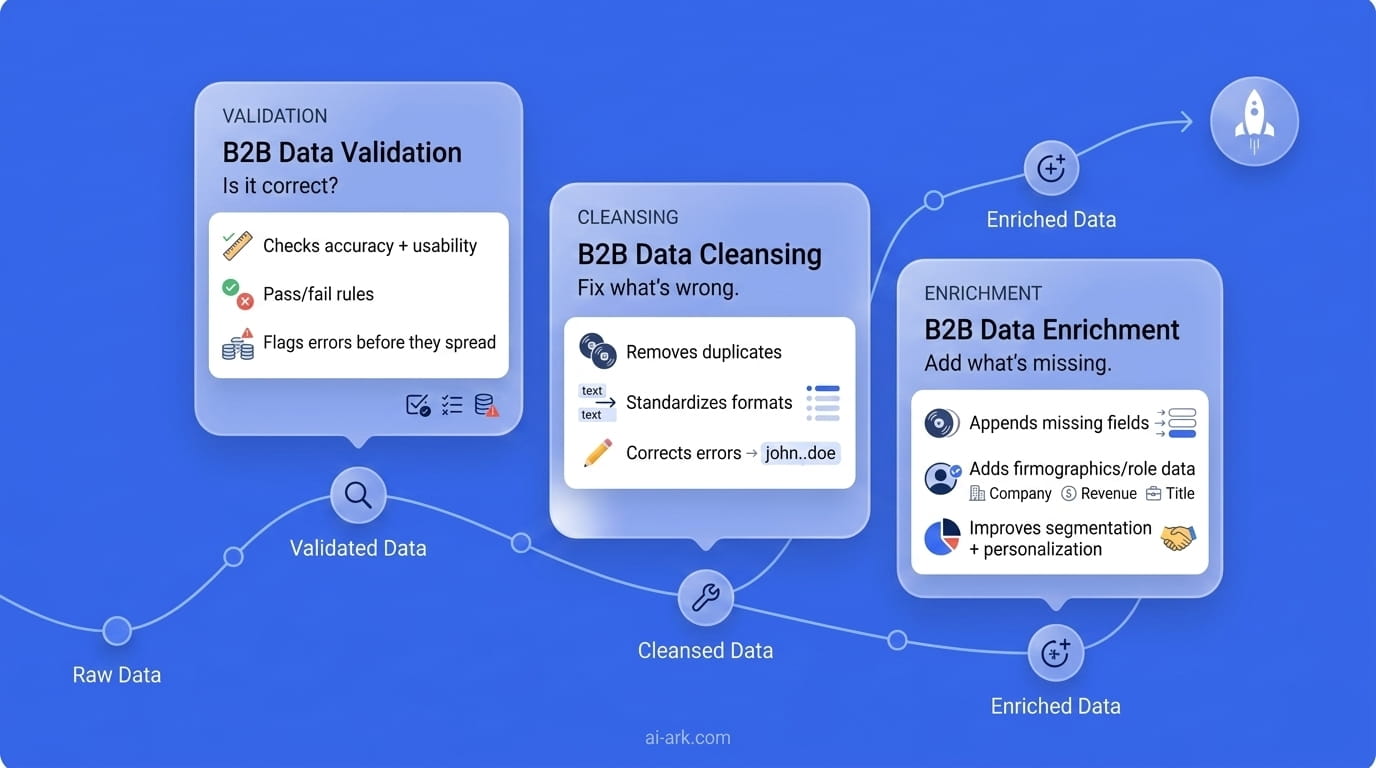
Here's the easiest way to understand it:
Validation is the inspection. It tells you if your data is correct and usable.
Cleansing is the repair. It will fix or eliminate the problems that validation has found.
Enrichment is the upgrade. It will give you new data points that you didn't have before.
You have to do all three. But just because you did one, it doesn't mean you did the other two.
Validation | Cleansing | Enrichment | |
|---|---|---|---|
What it does | Verifies accuracy | Fixes errors and removes bad data | Adds missing data points |
Example | Confirms an email is deliverable | Removes bounced emails from your list | Appends a job title to an existing record |
When it happens | Before or during use | After errors are identified | After validation confirms the base record |
Goal | Trust the data you have | Clean up what's broken | Fill in what's missing |
One mistake that people often make is going directly to data enrichment without validation. It is like home renovation, before checking if the foundation has any cracks, you will be wasting money on making poor data look more complete.
The 7 Data Fields That Need Validation
Validation is done for most teams on one or maybe two fields. Mostly email. Sometimes phone. And then they are done, assuming the rest is okay.

It's not. Here are the seven fields that require active validation and what happens when you don't validate each one:
1. Email Addresses The first and most frequently validated field, and for a good reason. Invalid emails will ruin your sender reputation, causing your deliverability rates to plummet, and this will negatively impact every campaign you send, even to perfectly valid addresses.
2. Phone Numbers A disconnected number is more than just a wasted dial. It's wasted research, prep work, and brain power that your SDR invested in that call. Format problems, old numbers, and landlines masquerading as mobile numbers quietly erode connect rates.
3. Company Names When "IBM," "I.B.M.," and "International Business Machines" appear as three distinct options in your CRM, you don’t have three accounts; you have one account and a deduplication problem. Non-standardized company names will blow up your segmentation, reporting, and ABM targeting.
4. Job Titles and Departments: Your outreach is only as good as your targeting. If your CRM indicates that someone is a VP of Marketing but they actually switched to a different department eight months ago, your personalized message is just irrelevant noise.
5. Mailing Addresses: Believe it or not, this still works in 2026, particularly for ABM campaigns that include direct mail, as well as territory mapping. Undeliverable addresses mean undelivered mail and wasted budget.
6. Firmographic Data: Revenue range, number of employees, industry codes. These data points power your segmentation and scoring engines. When they're incorrect, you're targeting companies that never should have been a good fit in the first place, or worse, missing ones that are.
7. Website URLs If the URL is broken or outdated, it’s impossible to determine what the company does, what technologies they are using, or if they are even in business anymore. A valid URL is a prerequisite for technographic profiling.
5 B2B Data Validation Myths That Are Costing You Pipeline
These are not harmless misconceptions. Each one of them creates a blind spot that quietly undermines your pipeline, and most teams don’t even notice the damage until they are left staring at a quarter of missed targets, wondering what went wrong.
Myth 1: "We Validate Emails, So Our Data Is Clean"
This is the most common pitfall in B2B data validation. This is very tempting because you can see the emails, you can measure the bounce rate, you can measure deliverability, and you can point to a number that says things are working.
However, email validation is just one of the many areas that need validation among at least seven. A record with a fully valid email address of someone who changed jobs six months ago is not clean data; it’s a waste of your SDR’s time. And this is more common than most teams realize. Studies have shown that 65.8% of B2B contacts change job titles within a year, and 42.9% change phone numbers within the same period of time. The email will still be delivered, but it will be delivered to the wrong person for the wrong reason.

What to do instead: Only validate on the data field that is easiest to measure. Email verification is the beginning, not the end.
Myth 2: "We Cleaned Our Database Last Year, We're Fine"
This is usually a tip that comes from teams that think data quality is a project that has a start and an end. They did a clean-up, removed some duplicates, fixed some formatting, and that was it.
The problem is that B2B data does not stay clean for very long. The rate at which contact information becomes outdated is approximately 2.1% per month, which means that 22.5% of your database will become outdated in a year. And the reasons are always the same. According to a report, every thirty minutes, 120 business addresses are changed, 75 phone numbers are updated, and 20 CEOs take on new positions.

The database you cleaned in January is already falling apart by March. By December, it might as well have never been cleaned.
What to do instead: Quit thinking of validation as a project. Integrate it into a process, real-time checks for new data, and quarterly sweeps for everything else. Your data isn’t stopping, so your validation can’t either.
Myth 3: "Our CRM Data Is Reliable Because Our Reps Enter It"
On the surface, this makes sense. Reps talk to prospects every day. They're closest to the customer. Their input should be the most accurate.
The truth is, salespeople are hired to sell, not to manage a database. They abbreviate company names differently each time. They don't fill out optional information because it won't result in a sale anyway. They copy job titles from LinkedIn profiles that are a year old. They enter a new record without checking if there's already one there, and before you know it, you have three records for the same person at the same company.
None of this is the reps' fault. This is what happens when you ask humans to be databases without giving them any guardrails. And the impact of this is huge, 40% of business goals fail because of wrong data, which is largely entered manually in the CRM.

What to do instead: Enforce validation rules at the time of entry into the CRM system. Format consistency, verification of required fields, and instantaneous duplicate checks should eliminate errors before they are even recorded. Don't ask the reps to be more accurate; make it more difficult for erroneous data to be entered.
Myth 4: "Purchased Lists From Reputable Providers Don't Need Validation"
You are paying high-end costs for data from a reputable source. It has already been validated, right?
Not necessarily. No data set is complete at the time of delivery, and the difference between what’s promised and what is delivered in your CRM may be larger than you think. On a list of 10,000 contacts, even a small error rate means hundreds of contacts that are stale, misformatted, or just plain wrong. And that’s from the better sources. The cheaper ones can be much worse.
There is also a timing issue. The providers check the data on their schedule, not on yours. By the time you buy a list, import it, and send out a campaign, weeks or even months may have elapsed since the last verification cycle by the provider. During this time, data decay is doing what it always does.
What to do instead: Validate every list before it reaches your CRM, no matter where the list came from. Consider all incoming data to be unverified until you can verify it yourself. It has nothing to do with trusting your vendor, and everything to do with the fact that no data set is ever 100% accurate all of the time.
Myth 5: "AI Will Fix Our Data Problems Automatically"
The AI hype cycle has created an expectation that machine learning can clean up any mess if you throw enough data at it. And AI genuinely is powerful for data validation; it can detect patterns humans miss, flag anomalies at scale, and automate checks that would take a team weeks to run manually.
But what's happening here is that the AI system is going to amplify whatever you put into it. If you're running an outreach sequence on unvalidated data, you're not just sending worse emails faster; you're amplifying bad decisions across your entire pipeline. This applies to predictive models, lead scoring, and segmentation as well.
The companies that are realizing the benefits of AI in data quality, about 37% of the companies, and are reporting an accuracy improvement of 30% in the first year, are the ones that are using AI automation in combination with validated inputs and human rules. The AI is not replacing their validation process. It is speeding it up.

What to do instead: Use AI as a validation tool, not a replacement for a validation strategy. Let AI handle pattern recognition, anomaly identification, and automation, but ensure that the data it is processing has already been subjected to your primary validation checks. AI helps good data become great. Bad data becomes worse, faster.
The B2B Data Validation Pyramid: Where to Focus First
Not all validation is created equal. The process of determining whether an email address is deliverable and whether a contact's job title is logically consistent with their company size are both examples of validation, but they are solving vastly different problems with vastly different levels of complexity.
This is why we use what we call the B2B Data Validation Pyramid, a structure for how to prioritize where to focus your validation efforts. Each level builds upon the level below it. Skip a level, and the levels above it are no longer valid.

Base Layer: Contact Validation
This is table stakes. If you're not doing this, nothing else in your go-to-market motion can be trusted.
Contact validation includes the two most basic fields in any B2B record: email addresses and phone numbers.
For email, this means more than just syntax validation. Does the mailbox actually exist? Is the domain up? Can it receive mail, or is it a catch-all mailbox that accepts everything and delivers nothing?
For phone, it means that you are verifying that the number is correctly formatted, currently connected, and hopefully able to distinguish between mobile, land, and VoIP numbers, since your SDR connect rate is contingent on understanding the distinction.
This is where most teams begin. This is also where most teams end, assuming that the rest of their database is in order, since bounce rates appear to be in good health. A valid email address combined with all the other bad data, however, is still bad data. It's just deliverable.
Middle Layer: Entity Accuracy
The base layer ensures that your outreach does not fail when you make contact. This layer is where you determine if you are reaching the right person with the right company.
Entity accuracy covers four areas:
Company name standardization: so the same company isn't showing up as five different variations in your CRM, shattering your segmentation and ABM targeting on what should be a single account.
Address verification: making sure that physical addresses are accurate and up-to-date for territory mapping, direct mail, and regional compliance.
Firmographic validation: verifying that the revenue range, employee count, and industry categorization in your database are still accurate. A company that has expanded from 50 to 500 employees since your last refresh doesn't belong in your SMB bucket anymore.
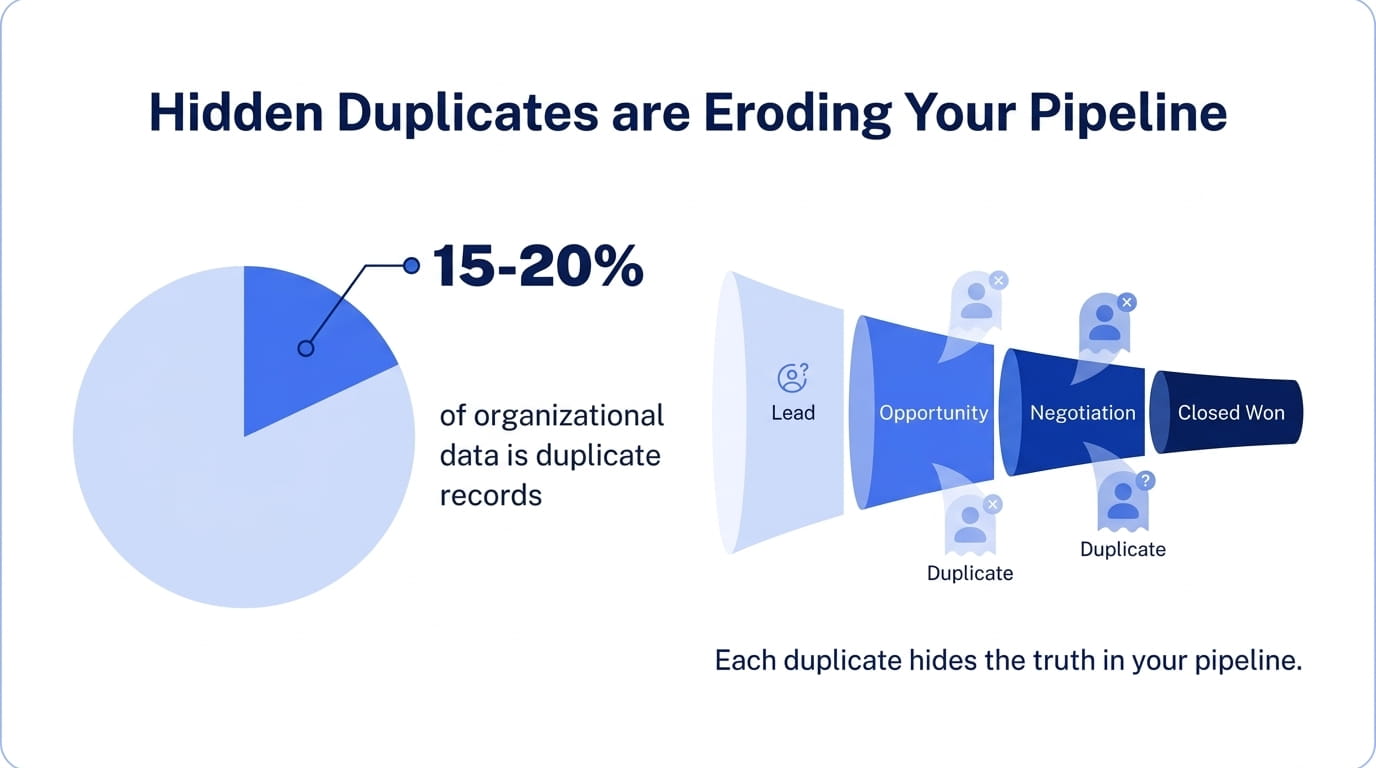
Duplicate detection and merging: identifying records that point to the same individual or company and merging them into a single clean record. On average, 15-20% of all organizational data contains duplicates, and each one clouds your pipeline visibility.
Most businesses that progress beyond the initial email validation level operate at this level. This is great, but it is not the whole story.
Top Layer: Contextual and Cross-Field Validation
This is where competitive advantage resides. And this is where almost nobody works.
Rather than verifying if each field is valid, this level of validation asks a different question: Does this record look valid as a whole?
A "VP of Engineering" at a five-person startup, is that really a VP-level decision maker? A company with $500K in revenue but 2,000 employees, does that pass a basic logic test? These don't show up in a standard field-by-field validation pass. But they'll ruin targeting accuracy when they get through.
But aside from cross-field checks, this level also involves anomaly detection, profiling your data statistically to highlight anomalies such as abrupt peaks from a single source, groups of entries that are suspiciously similar, or data that doesn’t conform to established market standards. And it also involves multi-source cross-referencing, checking entries against multiple reputable external sources rather than accepting a single source’s claims at face value.
This is also where AI really comes into its own. Pattern recognition, anomaly detection, and cross-referencing against millions of entries are exactly what machine learning is good at, provided the data it’s working with has already passed the first two levels.
Where Do You Sit on the Pyramid?
The majority of B2B businesses operate in the bottom tier. A select few have scaled into the second tier. Are the teams that are regularly filling the pipeline and meeting revenue goals? They're operating in the top tier, where data is not only valid line by line but also contextually valid.
That's the difference between a database that can send campaigns from versus one that can build a strategy from.
Real-Time vs Batch Validation: The Wrong Question Everyone Asks
Each and every guide on B2B data validation takes you through the same comparison. Real-time validation is the process of validating data as soon as it is entered. Batch validation is the process of validating data that already exists on a schedule. Choose the one that suits you.

This comparison completely misses the point.
The question isn't "which method should we use?" It's "where in our pipeline is data entering unchecked?"
Real-time and batch aren't competing options; they're different tools for different entry points. The correct solution is based on how data enters your ecosystem, not on a preference between two methods.
Here's how to map it:
Data Entry Point | Recommended Approach | Why |
|---|---|---|
Website forms and inbound leads | Real-time validation | Stop bad data at the door before it ever reaches your CRM |
Manual CRM entry by sales reps | Real-time validation rules | Catch formatting errors, missing fields, and duplicates the moment a rep hits save |
Purchased or imported lists | Batch validation before import | Screen the entire list for errors before it has a chance to pollute your existing database |
Enrichment API integrations | Real-time validation on receipt | Third-party data isn't automatically trustworthy; verify it as it arrives |
Existing CRM database | Scheduled batch sweeps (quarterly minimum) | Combat the ongoing decay that makes even validated records go stale over time |
Event and trade show leads | Batch validation within 48 hours | Event-collected data is notoriously messy, business cards get misread, forms get rushed, and details get entered from memory |
The solution for most teams is a combination of both approaches working in tandem, real-time catching issues at every entry point, batch processing what’s already inside. This is entirely dependent on where your data is coming from.
First, identify your entry points. Then, assign the correct validation approach to each. This is a system. Selecting "real-time" or "batch" as a preference is not a system.
The 8 Techniques That Separate Clean Databases From Expensive Liabilities
The validation pyramid shows you where to put your attention. These are the techniques that actually do the work. Each one addresses a particular point of failure, and missing any of these creates a hole that grows exponentially worse.
1. Email Verification
If your campaigns are bouncing and your domain reputation is falling, this is where it begins.
Email verification is more than just ensuring that an email address appears to be properly formatted. It verifies that the domain is in use, that the mailbox is valid, and that the email address is actually capable of receiving emails. Advanced verification also identifies catch-all domains, which are servers that accept all emails sent to them regardless of whether the particular mailbox is valid, and eliminates role-based email addresses such as info@ or sales@, which are rarely a conduit to a productive conversation.
Tip: Validate not only during import but also before each major send of a campaign. An email address may have been valid three months ago, but may not be valid today.
2. Phone Number Validation
Your SDR calls 60 numbers a day. How many of those are actually going to ring?
It's not a small problem. Sales teams are estimated to waste 27.3% of their time, or about 546 hours a year, chasing leads that are founded on bad data. Unconnected numbers are a huge part of that.

Phone validation ensures a consistent format regardless of country code or regional notation, verifies the number is in service at the time of validation, and determines the type of line: mobile, landline, or VoIP. The last one is more important than most teams understand. Mobile numbers have a significantly higher connect rate, and by knowing the type of line before you dial, you can allocate your team's time to the right numbers instead of wasting it on ones that aren't likely to answer.
Tip: Mobile numbers should be prioritized in your outreach campaigns. If you can't tell the difference between mobile and landline numbers in your data, that's a validation gap that should be addressed immediately.
3. Company Name Standardization
Three reps enter the same company into your CRM. One searches for "HubSpot," another for "Hubspot, Inc.," and the third for "HubSpot Inc." Well done, you now have three accounts for one company, and no easy way to report on any of them.
Company name standardization removes abbreviations, aliases, and formatting differences by matching against official records and reference works. It also deals with parent-subsidiary relationships, so you can see that the small regional office your SDR is currently prospecting actually exists as an enterprise account your team is already working with.
Tip: Standardize on import and retroactively on your current database. Otherwise, you'll have a partially clean CRM, which is arguably worse than one that's consistently messy, since you'll be more confident in the data than you should be.
4. Address Verification
The direct cost of returned direct mail is obvious. The hidden cost is every territory assignment, regional report, and location-based campaign that has been built on addresses that were never verified.
Address verification validates postal codes, verifies deliverability through postal authority databases, and uses geocoding to translate addresses into exact geographic points. For global databases, it also standardizes international formatting, because an address that is perfectly valid in one country's format may be unrecognizable to your systems in another.
Tip: Even if you don't run direct mail programs, validated addresses are what feed your territory mapping and regional segmentation. If those are wrong, your field team's entire coverage model is built on bad data.
5. Duplicate Detection and Merging
Two reps contact the same prospect a day apart with different messages. The prospect notices. Your credibility doesn’t bounce back easily.
Duplicate detection uses fuzzy matching algorithms to identify records that suggest the same person or business, even if they don’t appear to be the same on the surface, perhaps with slight variations in names, or variations in email domains for the same business, or records that are fragmented across different systems that never quite synced properly. Merging then combines all these records into one clean record, with the most up-to-date information from each duplicate.
Tip: Deduplicate before enriching. You’ll end up paying to enrich the same record twice, and you’ll create duplicates that look even more legitimate because now both copies are complete.
6. Cross-Field Validation
Each field in your data could be subject to its own set of tests and still have a narrative that doesn't quite add up.
Cross-field validation looks at the logical connections between data points in a given record. It identifies patterns that don't make sense: "Director of Engineering" as a title for someone in the marketing department, a company with 10 employees that reports $500 million in revenue, or someone in one time zone with a phone number in another. These are the kinds of errors that won't show up in a typical validation check, but are precisely the kind that will lead to misguided outreach and wasted effort.
Tip: This is the area where most teams don't even bother to check, and where the biggest mistakes in targeting are hiding. Even a simple set of cross-field checks (title vs. department, company size vs. revenue) will turn up problems that no amount of email validation will reveal.
7. Data Profiling and Anomaly Detection
If you're only catching the errors you already know to look for, you're missing the ones that matter most.
Data profiling looks at your data as a whole, not on a record-by-record basis. It looks at distributions, patterns, and statistical norms to identify outliers that point to quality issues, an unusual number of records from a single source, an abrupt spike in records with the same formatting, or data values that are outside the expected ranges for your industry or market. Anomaly detection takes this a step further by using algorithms to identify data points that don't conform to established patterns, even if it's too subtle to spot by eye.
Tip: Profile every list you buy before importing it. If the anomaly rates come back high, dispute the list before it gets imported into your system. It's cheaper to reject a bad list than to clean it up after it's been merged into your CRM.
8. Third-Party Source Cross-Referencing
A record that verifies out against one source could still be incorrect. A record that verifies out against three or four definitely isn't.
Third-party cross-validation verifies your data against multiple independent external sources: government records, public business filings, reputable data vendors, and industry-specific directories. The more sources that verify a piece of data, the greater your confidence level. This is particularly important for firmographic and contact data, where one source's data may be stale while another source's data has already been updated.
Tip: This is what distinguishes good-enough data from data you can actually make strategic decisions with. If your current verification process only checks data against one external source, you're verifying, but you're not cross-validating. There is a world of difference between the two.
Metrics That Prove ROI (B2B Data Validation KPIs)
But validation is only worth investing in if you can show that it is effective. Not conceptually, but in numbers that your leadership team is actually interested in.
The problem with most teams is that they look at the quality of the data in a vacuum. Duplicate rates and completion percentages are important, but they are not particularly useful in a quarterly business review unless you can tie them back to revenue results. The key is to measure the impact of validation at four levels.

Deliverability Metrics
These are the first signs that validation is working. If your data is clean, you should see this first.
Bounce rate: the most straightforward measure. A validated email list should keep hard bounces at or below 2%. If it’s higher, it means that your invalid addresses are getting through, and each bounce erodes your sender reputation for future mailings.
Spam complaint rate: indicates whether you’re reaching people who actually want to hear from you. Increasing complaints are a sign that your data is putting you in front of the wrong roles, the wrong companies, or people who were never a good fit.
Inbox placement rate: looks beyond open rates to see how many messages that actually get through end up in the main inbox versus the spam or promotions folder. Clean data helps maintain your sender reputation, which is the direct factor in where your messages land.
Sales Efficiency Metrics
This is where validation begins to pay off in terms of time saved and conversations initiated. Four metrics tell the story:

Connect rate is the rate at which reps actually connect with a human when they call. Validated phone numbers, particularly if you've separated mobile from landline numbers, will significantly boost this metric. If connect rates aren't improving, likely that your phone data hasn't been validated in a while.
Reply rate on outbound email is a measure of whether you're actually reaching humans with messages that matter to them. Validation won't cure a messaging problem, but it will remove the invisible floor that bad data creates for your response rates. You can't get a reply from someone who never got your email.
Meetings booked are what sales leadership is monitoring most closely. The more validated contacts, the more conversations that actually happen with the right person, fewer no-shows, fewer "wrong department" calls, and less wasted cycles.
Time-to-first-touch measures the speed of contacting a new lead. If reps trust the data in front of them, they will stop manually verifying the record before making a call. Validation reduces the time between lead capture and first touch, and this time is important because the sooner you contact a lead, the higher your chances of conversion.
Funnel and Revenue Metrics
This is where validation becomes a boardroom conversation.
Metric | What does it tell you | How validation moves it |
|---|---|---|
MQL to SQL conversion | Are marketing leads actually workable by sales? | Meaningful titles, companies, and contact information mean leads that pre-qual on paper also pre-qual in reality |
SQL to Opportunity conversion | Are sales conversations turning into a real pipeline? | Better firmographics mean reps are spending time on accounts that actually match your ICP |
Pipeline created | How much revenue potential is entering your funnel? | More accessible, relevant leads from the same outreach effort |
CAC efficiency | How much are you spending to acquire each customer? | Less money wasted on undeliverable campaigns, dead-end outreach, and nowhere-to-go cycles, same budget, more ROI |
Data Quality Metrics
These are the internal health checks that will give you insight into whether your validation process itself is working. Monitor all four, but focus on the last two, as most teams don’t.

The rate of duplicates and the percentage of field completeness are the normal ones. Once validation has been put in place, the rate of duplicates should plummet and remain low. Completeness will give you insight into where there are still holes in the records that need to be enriched.
"Last verified" freshness percentage is perhaps the least leveraged B2B data metric. It measures the percentage of your database that has been verified within a certain time frame, such as the last 90 days. If only 40% of your database has been verified recently, then the remaining 60% is expiring, whether you know it or not.
Invalid rate by source allows you to see the quality of your data by source, which includes forms, purchased lists, event leads, manual entry, and API integration. This is how you determine which sources are providing good data and which sources require more validation or need to be abandoned altogether.
5 KPIs Every B2B Team Should Track After Implementing Data Validation
Email bounce rate: target below 2% to protect sender reputation and deliverability
Connect rate: measure how often reps connect with a live person to determine phone data accuracy.
MQL-to-SQL conversion rate: track if qualified leads actually convert to sales-accepted opportunities
Duplicate rate: monitor to ensure deduplication is effective
Last verified freshness %: measure what percentage of your database has been verified in the last 90 days
How AI Ark Builds Validation Into Every Record
Every aspect of this guide indicates one key change: validation can’t be an afterthought. It has to occur before your data even gets to your team, not after it’s already caused issues.
This is how we created AI Ark.
Rather than providing you with the data and being done with it, waiting for you to validate it, AI Ark uses multiple levels of validation on every record before it even gets to your CRM. This allows us to provide you with a database of over 15 million people profiles and 1 million company profiles at 95% data accuracy with a 30-day refresh cycle.
Here’s how that translates to the validation pyramid:
The base layer is covered because contact-level validation for emails and phone numbers is automatic. Incomplete or invalid contact information means the records won’t appear in your search results.
The middle layer is covered because company information is validated against firmographic databases using AI Company Search, and AI People Search validates contacts against the correct company with the correct titles and positions.
The top layer is covered because AI Similarity Search and AI Semantic Search use cross-referencing to provide accurate and relevant search results, not just based on keyword or field matching.
For teams that already have data and want to keep it fresh, the Enrichment API ensures that your existing data is validated and updated in real-time, filling in the blanks, fixing outdated information, and making sure that what’s already in your CRM stays up to date as your database gets older.
The bottom line: your team should be focused on outreach and strategy, not data scrubbing. Validated data out of the box is how that happens.
Schedule a demo to see how AI Ark provides pre-validated B2B data at scale or start your free trial and test the data for yourself.
FAQs About B2B Data Validation
1. What is B2B data validation?
B2B data validation is the process of ensuring that business contact and company information is accurate, complete, formatted correctly, and usable. This includes checking information such as email addresses, phone numbers, job titles, company names, and firmographic information against set rules and trusted external sources before that information is used for sales outreach, marketing, or business analytics.
2. What is the difference between data validation and data verification?
Data validation: This is the process by which the system checks if the record satisfies your set standards of quality is it properly formatted, is it complete, does it logically make sense? Data verification: This is the process by which the system checks if the data is actually true by matching it against other sources. In B2B, good data validation would be the combination of both.
3. How often should you validate B2B data?
B2B data needs to be validated on an ongoing basis, not as a one-time clean-up process. The best practice is to validate new data in real-time as it comes in and perform batch validation on your existing database at least once a quarter. Business contact information becomes outdated much faster than most teams realize, with people changing jobs, phone numbers going down, and companies restructuring all the time.
4. What are the most common types of B2B data validation?
The most popular ones include email verification, phone number verification, business name standardization, address verification, duplicate detection, cross-field validation, anomaly detection, and third-party source verification. What most teams begin with is email and phone number validation, but to have quality data, all key fields must be validated, not just the ones that are easiest to measure.
5. Is email validation enough to keep B2B data clean?
No. Email verification is critical, but it only validates one field. Having a record with a verified email address but an outdated job title, incorrect company name, or no longer valid phone number is still poor data; it’s just valid poor data. Validating B2B data requires verification against at least seven key fields: email, phone, company name, job title, address, firmographics, and website URLs.

